https://www.thechurchnews.com/members/2021-10-29/computer-assisted-indexing-familysearch-records-231067This article is interesting from several different aspects. First, there are some interesting and updated statistics. Here is a quote with some of the statistics from the above linked article to start out.
In September, FamilySearch announced a milestone 83 years in the making — the completion of digitizing its collection of more than 2.4 million rolls of microfilm.
The digital archive containing information on more than 11.5 billion people represents over 200 countries and principalities and more than 100 languages.
The reference to “83 years in the making” is obscure. This refers to the date of the first microfilm efforts in 1938. Hence, 83 years. FamilySearch hasn’t been digitizing for nearly that long. It is the case, however, that some of the early microfilms have been indexed. The next statement in the news article has got to be the genealogical understatement of the year.
While images of these records are available to view online, several records still need to be indexed so FamilySearch users can search for and find them. Many of those languages, however, are difficult for people to index.
I think the writer of the article left out the word “billions” after the word several. For some time, I have been watching to see how many of the billions of records on the FamilySearch.org website have been digitized. The number of digital images (as opposed to people represented by those images) is about 4.6 billion according to the Company Facts section of the FamilySearch.org website. Now to the percentage of records that are not yet indexed, again quoting from the article above.
Only 20% of FamilySearch’s online historical records are currently indexed, and FamilySearch hopes computer-assisted indexing can increase that percentage at an accelerated pace.
My most current estimates ran at about 30% which is a figure I have heard several times from FamilySearch. However, more recently, FamilySearch has been uploading raw digitized images to the Image Section of the website.
Optical Character Recognition (OCR) has been available for years and is very sophisticated. I have always wondered why FamilySearch did not utilize this existing technology to assist in indexing. It appears that they may have now started to do so. Of course, they use OCR to digitize their online books collection that presently stands at about 531,909 and is increasing weekly.
It isn’t clear from the article exactly how FamilySearch is using artificial intelligence to assist in indexing, but I can guess that they are relying on research done by the Brigham Young University Family History Technology Lab in part. You might want to read the article for yourself and see what you think.
Here is another quote.
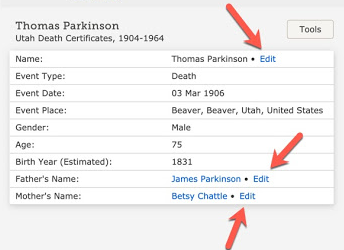
Records indexed by a computer are labeled with a box in the top right corner that reads “This record was indexed by a computer. If you find an error, click here to report it.”
I have yet to run into any of these records. I am aware of the obituaries that were transcribed by OCR that allowed corrections, but I have been asking for years why FamilySearch does not crowdsource their indexing online with user transcriptions of individual records as they are searched. Here is the record shown in the article.

Now back to the issue of the images. It is apparent to me that the number of images that are unindexed is growing faster than the effort to index them. This is likely the incentive for FamilySearch’s automated indexing efforts.