Understanding Merging on the FamilySearch Family Tree
Note: This article by James Tanner was published previously on the Genealogy’s Star blog site.

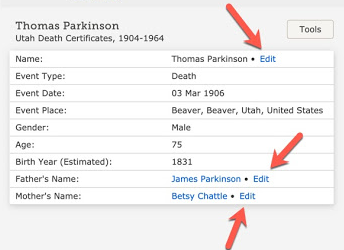
The FamilySearch.org Family Tree was originally seeded with previously collected individual and family histories from five major collections: the Ancestral File, the Pedigree Resource File, the International Genealogical Index, and Membership and Temple records from The Church of Jesus Christ of Latter-day Saints. These records were not directly added to the Family Tree. They were previously used as the basis for the new.FamilySearch.org website. By using these databases, the release of the FamilySearch.org Family Tree automatically had millions of duplicate entries. As an example, the individual shown above is a duplicate entry. Here is the entry that appears in my view of the Family Tree.

Some time ago, FamilySearch implemented a program routine that eliminated millions of these duplicate records. In addition, users of the website have been working to eliminate a significant number of additional duplicates not detected by the FamilySearch program. Notwithstanding this effort on behalf of both, there are still a significant number of duplicate entries in the FamilySearch Family Tree.
As a result of this duplication, FamilySearch has implemented sophisticated features to detect and merge duplicates. As you work with the website, you will see notices of duplicate records. What if the duplicates do not appear.

If you recognize that this person is a duplicate, despite the lack of a notice from FamilySearch, you can merge the two individuals using ID numbers. But you can also have the program look for similar people. Beginning with the first person above, I looked for similar people using alternative spellings of the surname. I soon found the following similar individuals.

The program immediately found the duplicate. So now we have Jacob Abraham DeVries 29CP-HH5 and Jacob Abraham De Friez BM9R-QX1. Another place that a duplicate might show up is when you look for records. The record search will show the person with a record attached that matches your person. There are some limitations and you may have to search with alternative names. Here is an example using some alternative spelling.

These examples are certainly not all the places duplicate show up that are not detected by FamilySearch. Another common example is when you see children in a family with the same name. It is possible that one child died young and the next child of the same sex was given the same name as the deceased child. This practice was common in many European countries and possible elsewhere around the world. This means that two or more children with the same name must not be assumed to be duplicates but very well may be.
When you create a new person for the Family Tree, the website will look for a match.

If you find that there is a duplicate, you can choose to use the existing person and stop trying to create a new person thus avoiding a duplicate. If you create a new person, there will then be an additional duplicate on the website.
Merging the duplicate is straightforward. When a duplicate is found by FamilySearch, you simply follow the directions and compare the two individuals and then merge them if they turn out to be duplicates. But in the examples I have given, you need to merge the duplicates by ID number.

You can then proceed to compare and then merge the two people. At this point, you will have already made the decision that the two people are duplicates so the process should be easier than comparing two individuals that a suggested by FamilySearch as duplicates.
If you continue with the merge process, the issue is whether the two people match and are really duplicates. In all these cases, not all of the information needs to be the same. Variations in names and dates are common but different places need to be examined carefully. Two people can have the same name, the same spouse’s name, and some of the children with the same names but when the places are different this raises an issue requiring more research. Here is an example of a situation where all the pertinent information is the same.

The person who survives should be the one with the most correct information. The process allows you to choose which entries will be preserved in the merging process.
After a careful review, if you decide to merge the two records, You will be asked to provide a reason for the merge. Here are the stock answers from FamilySearch.

You need to make a choice and finish the merge. The merged record is still in existence but is marked as deleted. As long as no further changes are made, you can unmerge the records by viewing the Change log. If this all seems to be complicated, it is. But once you find a few duplicates and go through the process, you will find it to become fairly routine with some notable exceptions.

If you need additional help, see The Family History Guide section on Merging in the FamilySearch Family Tree.